📝
*試験対策用のメモ✍
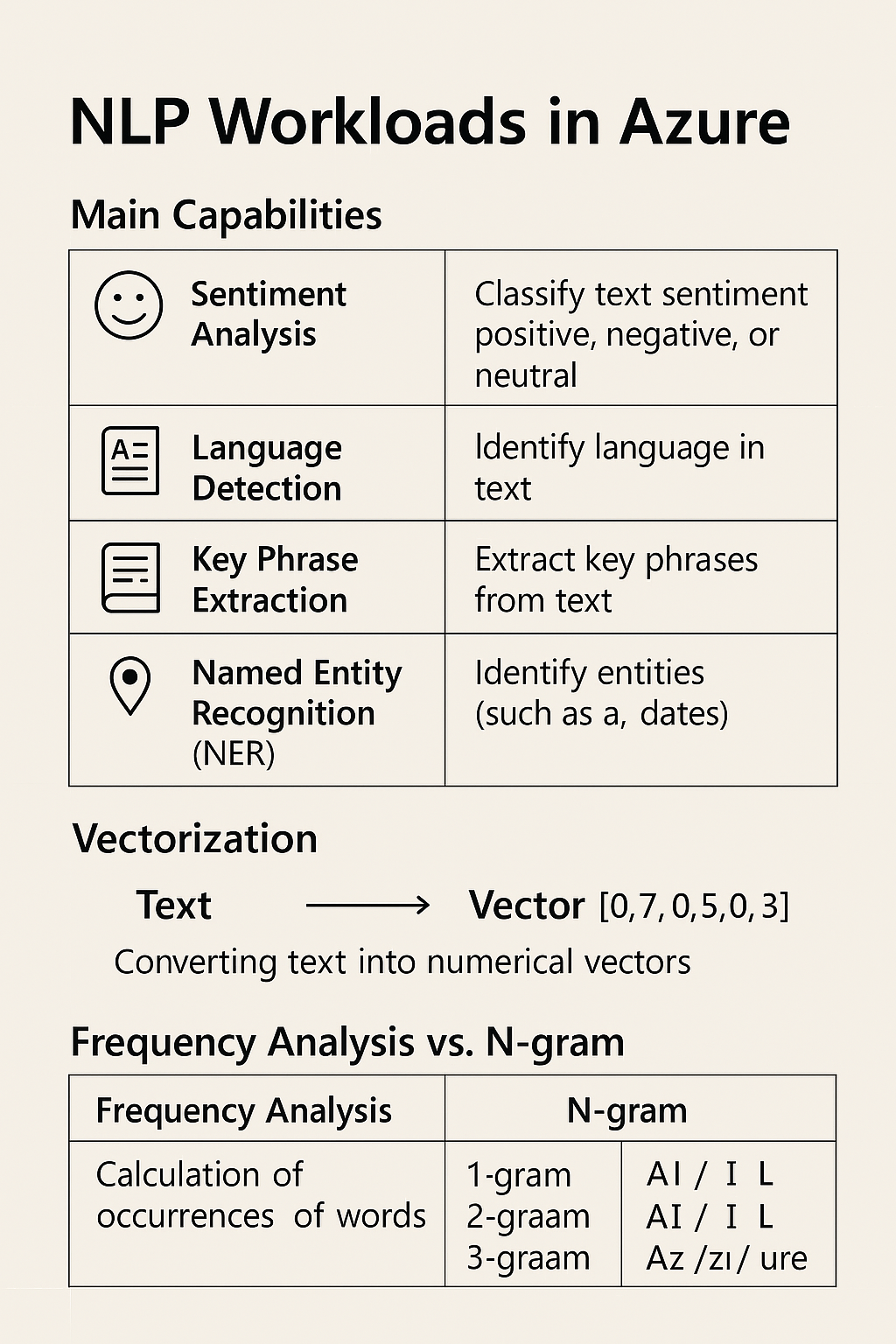
① Azure の NLP(自然言語処理)ワークロードの主な機能
Azure の Text Analytics サービスでは、文章から意味や情報を取り出すことができるよ!
| 機能名 | 説明 | 例 |
|---|---|---|
| 感情分析 (Sentiment Analysis) | 文章の感情を分類(ポジティブ/ネガティブ/中立) | 「最高!」→ ポジティブ |
| 言語検出 (Language Detection) | 文章が何語かを判定 | “Hello” → 英語 |
| キーフレーズ抽出 (Key Phrase Extraction) | 重要な単語やフレーズを抽出 | 「AzureでAIを使う」→「Azure」「AI」 |
| 名前付きエンティティ認識 (NER) | 人名・地名・会社名などの固有名詞を抽出 | 「田中さんが東京で会議」→「田中(人名)」「東京(地名)」 |
👉 これらはすべて「テキストを数値化(ベクター化)」して分析しているよ!
たとえば、カスタマーサポートに届いたメールの山を Azure に読ませて…
どんな気持ちの内容か(感情分析)
どの言語で書かれてるか(言語検出)
重要なキーワードは?(キーフレーズ抽出)
出てきた会社名や人名は?(エンティティ認識)
を全部機械が読み取ってくれる!
② ベクター化ってなに?
テキスト(文章)を、AIが理解できる数字のかたまりに変換すること!
🔢 例:
-
「おはよう」→
[0.7, 0.1, 0.5, 0.3] -
「こんにちは」→
[0.6, 0.2, 0.4, 0.4]
📌 ポイント:
-
AIは文字のままでは意味がわからない
-
だから、単語を「数字で表現」して、意味の近さや文脈を理解できるようにする
🎯 使用場面:
-
検索、類似文比較、感情判定など、ほぼすべてのNLP処理の前提になる
③ 頻度分析 vs N-gram(違いと使い分け)
🟡 頻度分析(Frequency Analysis)
単語ごとの出現回数を数える分析手法
🔍 目的:よく使われる単語を知りたいとき
| 単語 | 出現回数 |
|---|---|
| わたし | 1 |
| は | 1 |
| AI | 2 |
| が | 1 |
| 好き | 1 |
| って | 1 |
| 便利 | 1 |
| だよね | 1 |
🟢 N-gram(エヌグラム)
単語をN個ずつのセットで分割する方法(文脈や語の並びを捉える)
🔍 目的:単語のつながり・文脈を分析したいとき
| N | 分析単位 | 例(「わたし は AI」) |
|---|---|---|
| 1-gram | 1語ずつ | わたし / は / AI |
| 2-gram | 2語ずつ | わたし は / は AI |
| 3-gram | 3語ずつ | わたし は AI |
🔁 使いどころ:
-
自然な文章予測(例:変換候補や予測変換)
-
類似パターンの発見
④ 頻度分析とN-gramの比較表
| 比較項目 | 頻度分析 | N-gram |
|---|---|---|
| 分析単位 | 単語単体 | N語のセット(連続) |
| 分析目的 | よく出る単語を知る | 単語のつながりを見る |
| 用途 | キーワード抽出・要約 | 文脈理解・予測変換 |
| 特徴 | 単純で早い | 精度高いけど手間がかかる |
📝 補足:AI-900試験に出そうなポイント
-
「ベクター化」は、テキストを数値に変換することでAIが意味を理解できるようにする仕組み。
-
Text Analytics の各機能(感情分析、言語検出など)は、裏でこのベクター情報を使って判断してる。
-
N-gram は「文脈」や「意味の流れ」を分析するための特徴量エンジニアリング手法の一つ。

☕ Share this post






.png)
.png)
💬 コメントしてみる?